Link State Routing
각 라우터가 자신과 직접 연결된 링크의 상태 정보를 네트워크 안의 모든 라우터에게 알려주고, 모든 라우터가 동일한 네트워크 지도(토폴로지)를 그린 뒤 그 지도를 보고 직접 최적 경로를 계산하는 알고리즘이다. OSPF, IS-IS 등이 있다.
Distance Vector가 "이웃이 알려주는 거리 정보를 그대로 믿고 따라가는 방식"이라면, Link State는 "네트워크 전체 지도를 보고 내가 직접 길을 찾는 방식"이다.
동작 과정
Link State는 다음과 같은 흐름으로 경로를 결정한다. 전체 단계를 한 장으로 요약하면 다음과 같다.

1. Hello 패킷 교환
각 라우터는 인접한 라우터(Neighbor)와 Hello 패킷을 주고받아 이웃 관계를 형성한다. Hello 패킷에는 자신의 Router ID와 인터페이스 정보가 담겨 있고, 양쪽이 서로의 ID를 확인하면 2-Way 상태가 되어 정식 이웃으로 인정된다.

2. LSA 광고 (Flooding)
자신과 직접 연결된 링크 정보(상대 라우터, 대역폭, 비용 등)를 LSA(Link State Advertisement)로 만들어 네트워크 전체에 전파(Flooding)한다. 각 라우터는 LSA를 받으면 자신의 데이터베이스에 저장한 뒤, 받은 인터페이스를 제외한 나머지 인터페이스로 다시 전달한다. 이런 방식으로 LSA가 네트워크 안의 모든 라우터에 도달한다.
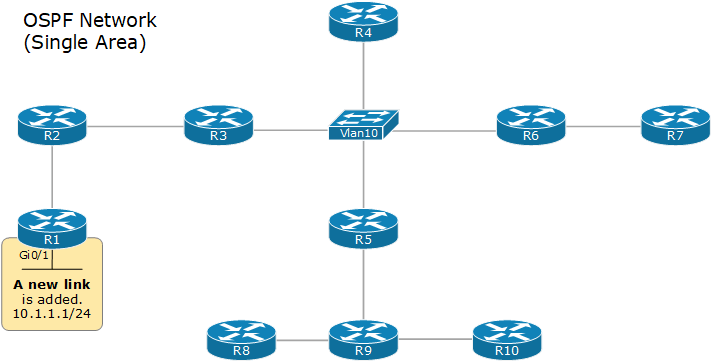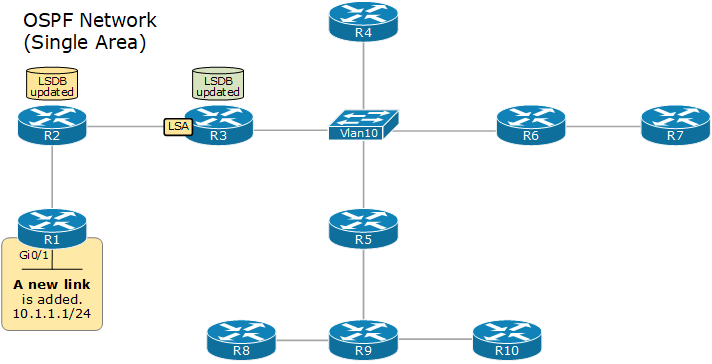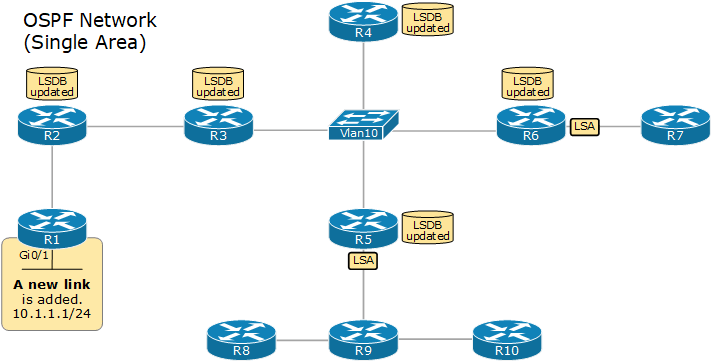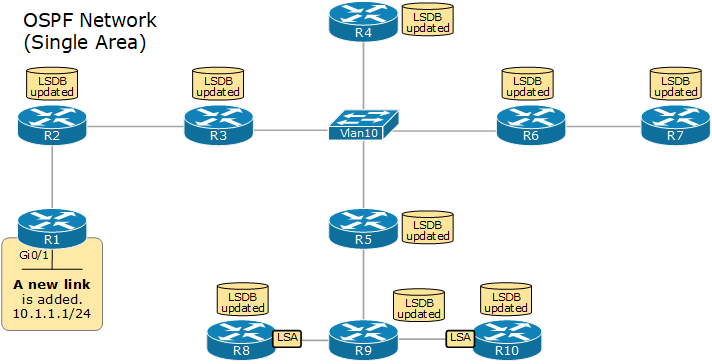
3. LSDB 구성
모든 라우터는 수신한 LSA를 모아 동일한 LSDB(Link State Database), 즉 네트워크 전체의 지도를 가진다. 같은 영역(Area) 안의 라우터는 LSDB가 완전히 동일해야 정상적으로 동작하며, 이 LSDB가 다음 단계인 SPF 계산의 입력값이 된다.
4. SPF 계산
각 라우터는 LSDB를 기반으로 SPF(Shortest Path First, 다익스트라) 알고리즘을 돌려 자신을 기준으로 한 최단 경로 트리(SPF Tree)를 만들고, 그 결과를 라우팅 테이블에 반영한다. 같은 LSDB라도 라우터마다 시작점(자기 자신)이 다르기 때문에, 각자 다른 모양의 트리가 만들어진다.

특징
- 전체 토폴로지를 안다: 단순히 이웃이 알려주는 거리 정보만 받는 게 아니라, 네트워크 전체의 연결 상태를 직접 파악한다.
- 변경이 있을 때만 광고: 평소에는 트래픽을 거의 발생시키지 않다가, 링크 상태가 바뀌었을 때만 LSA를 보내는 트리거 방식이다.
- 수렴(Convergence)이 빠르다: 변경 사항이 즉시 전파되고 각 라우터가 직접 경로를 다시 계산하므로, Distance Vector보다 변화에 빠르게 대응한다.
- 루프 가능성이 적다: 모든 라우터가 같은 지도를 보고 스스로 경로를 계산하므로, Distance Vector에서 자주 문제되는 라우팅 루프가 발생할 가능성이 적다.
- 자원 사용량이 크다: 전체 네트워크의 LSDB를 저장하고 SPF 알고리즘을 계산해야 하므로, Distance Vector에 비해 CPU와 메모리를 더 많이 사용한다.