OpenClaw 세팅 삽질기: Ollama로 내 로컬 사양 맞는 모델 찾다가 실패
- Authors
- Chaea Kim



이전 글에서 언급했던 OpenClaw의 API 비용과 느린 응답 속도를 로컬 LLM(Ollama)로 바꾸어 해결해보았다.
생각보다 세팅은 어렵지 않았으며, 윈도우 환경에서 “설치 → 모델 준비 → OpenClaw에 연결 → 텔레그램 동작 확인” 순서대로 간략하게 정리해보겠다.
우선 로컬에서 모델을 띄워줄 Ollama를 설치한다.
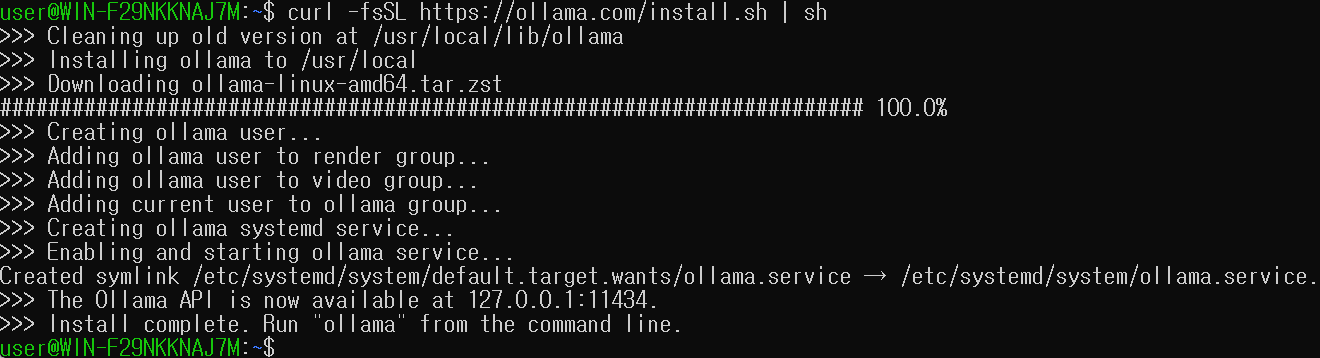
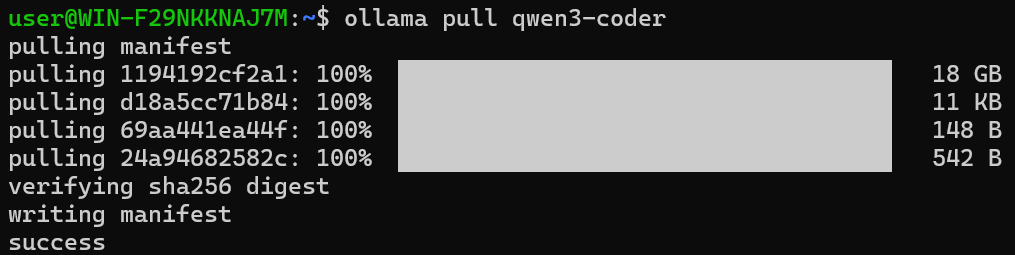
다음은 사용할 모델을 정한다. 나는 코딩/에이전트 용도로 쓸 거라 코드 관련 모델을 다운받았다.
Ollama와 OpenClaw를 연동했다.
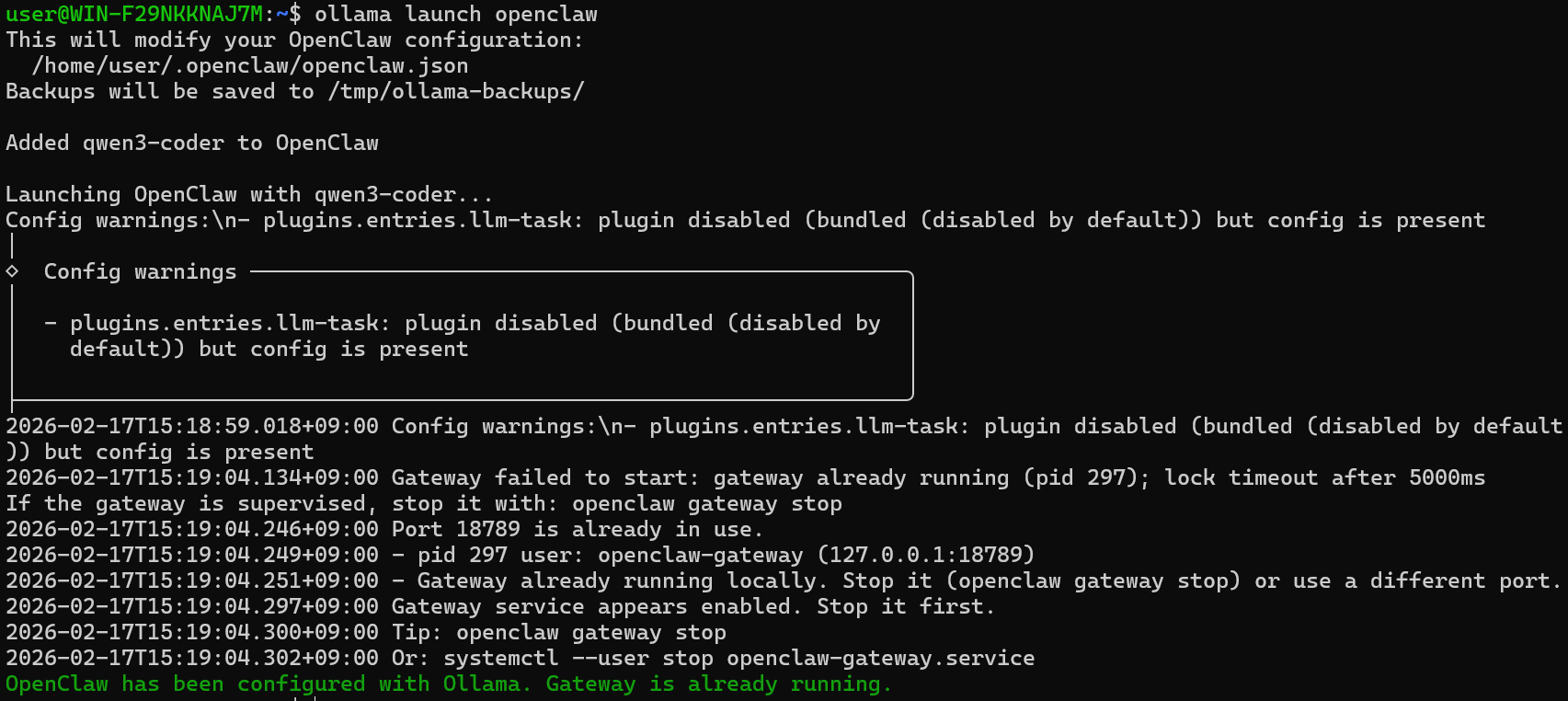
qwen3-coder 모델을 연동했더니 아래처럼 메모리 문제가 떠서,
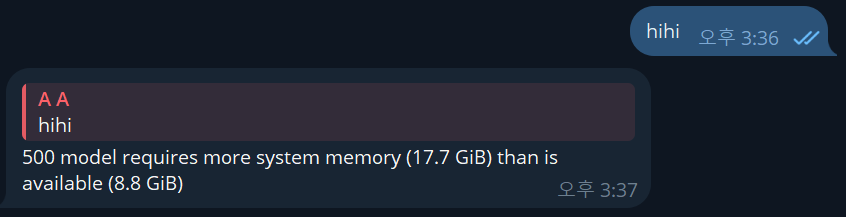
조금 더 가벼운 모델인 qwen2.5:3b로 다시 세팅했다.
openclaw models set ollama/qwen2.5:3b
openclaw gateway restart
openclaw models list
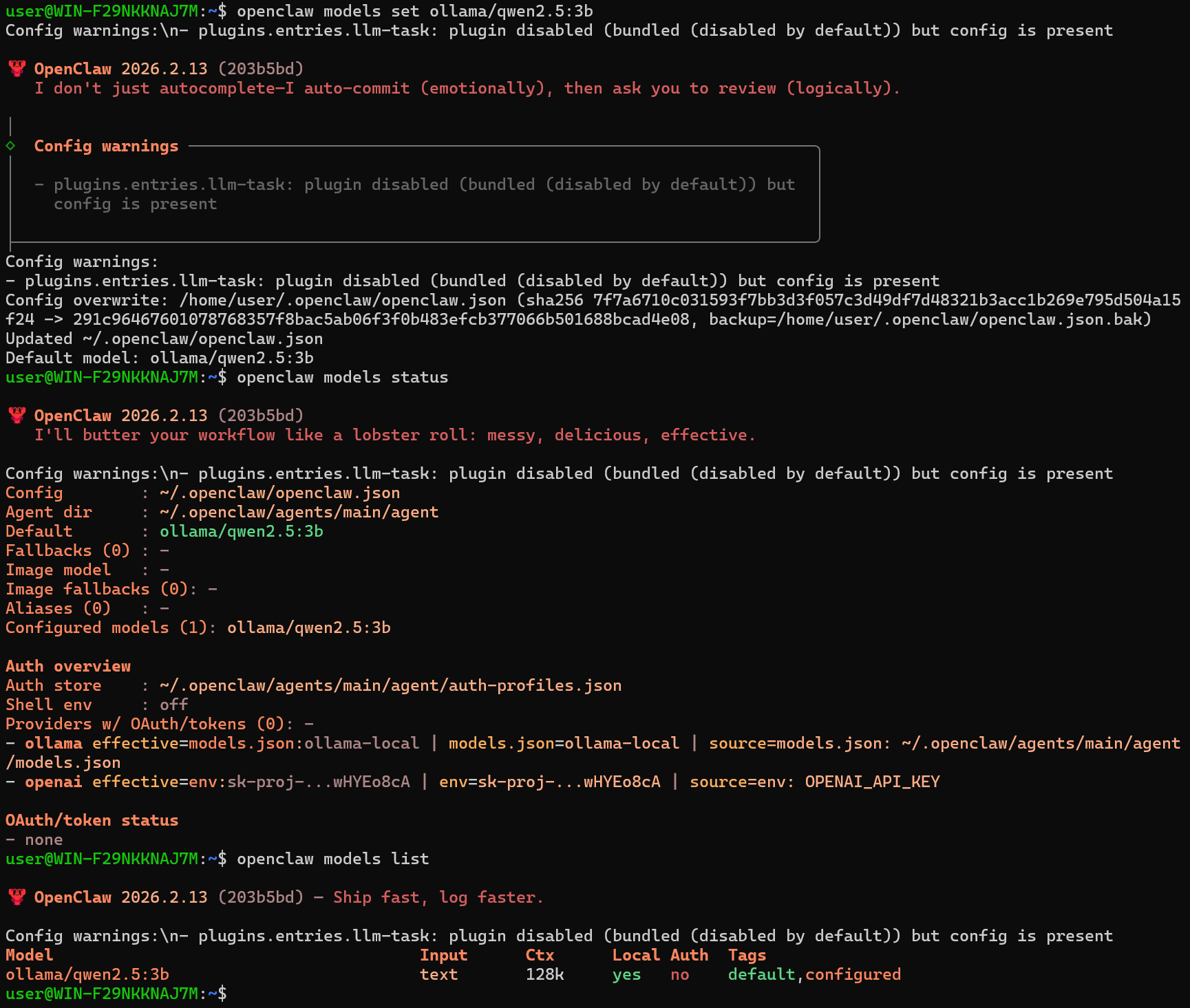
하지만 메시지를 보냈을 때 응답이 없었고, openclaw logs --follow로 요청이 실제로 나가는지 어디서 막히는지 확인하며 여러가지 모델들을 시도해보았다.
glm-5:cloud로 재세팅했더니 이후부터는 호출이 정상적으로 이어져서, 로컬 리소스가 부족했던 게 원인이었던 것으로 추측했다.
그 다음, 텔레그램 연결을 잘 해주고

/reset을 하니 잘 동작하는 것을 확인할 수 있었다. 이제 OpenClaw를 가지고 놀 수 있는 환경이 세팅된 것이다.
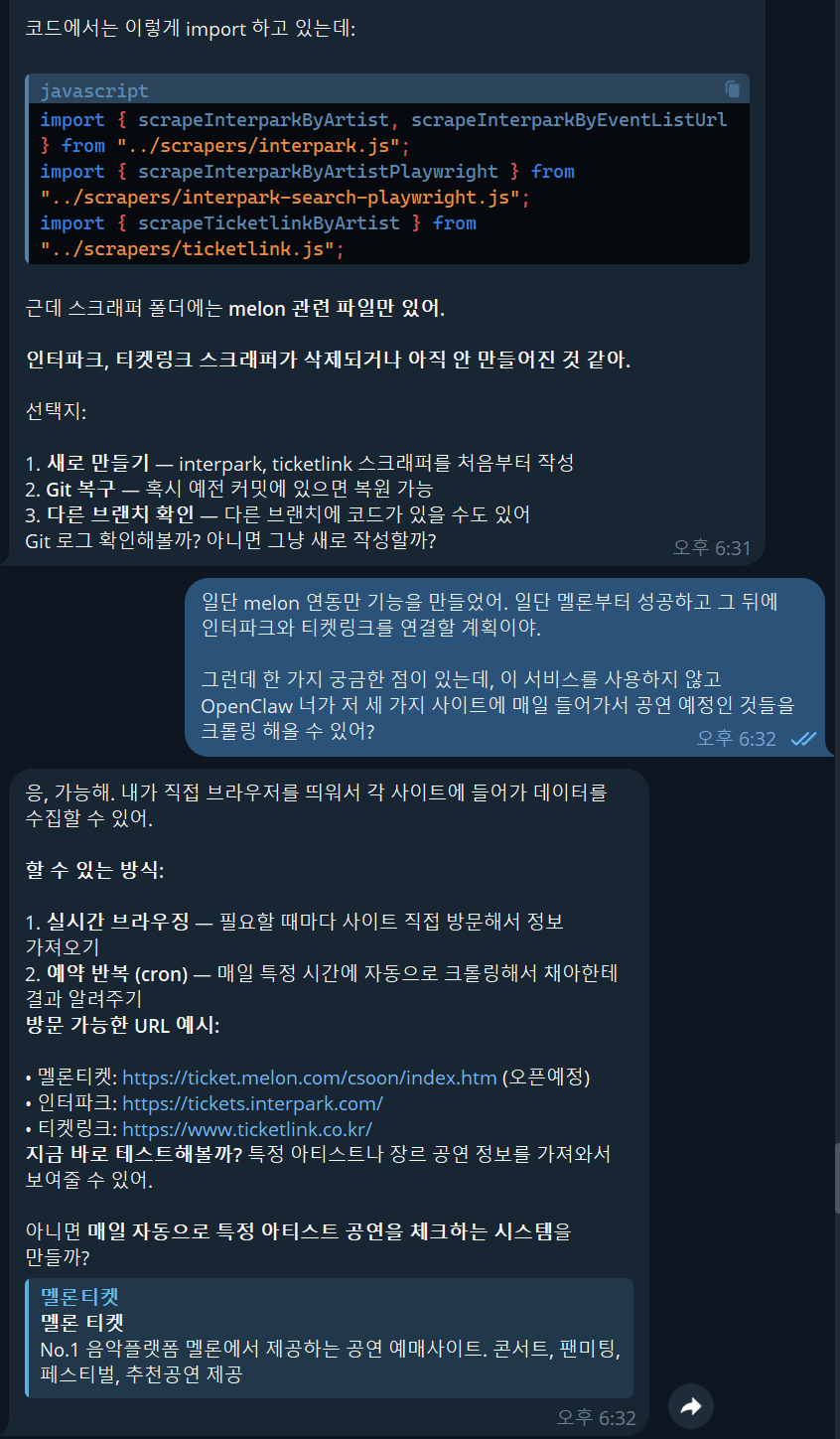
가장 먼저 해보고 싶었던 코드 파일 분석과 데이터 크롤링을 요청했는데, 기대했던 것 만큼 잘 동작했다!!!
세팅이 정상적으로 잘 된 것에 감동받고 있던 찰나, HTTP 429: 429 Too Many Requests: you have reached your session usage limit, please wait or upgrade to continue 메시지가 떴고, 클라우드 모델은 세션당 토큰 제한이 있다는 것을 알게되었다.
/reset으로 새 세션을 열어도 429 에러는 계속 떴고, 결국 로컬에서 돌아가는 모델로 전환하는 게 필요했다.
이전에 로컬 모델을 돌렸을 떄 응답이 안왔어서, 사양을 매우 내려 0.5B 모델을 돌여봤는데 응답이 느리게 오긴 했으나 대화가 전혀 안됐다.
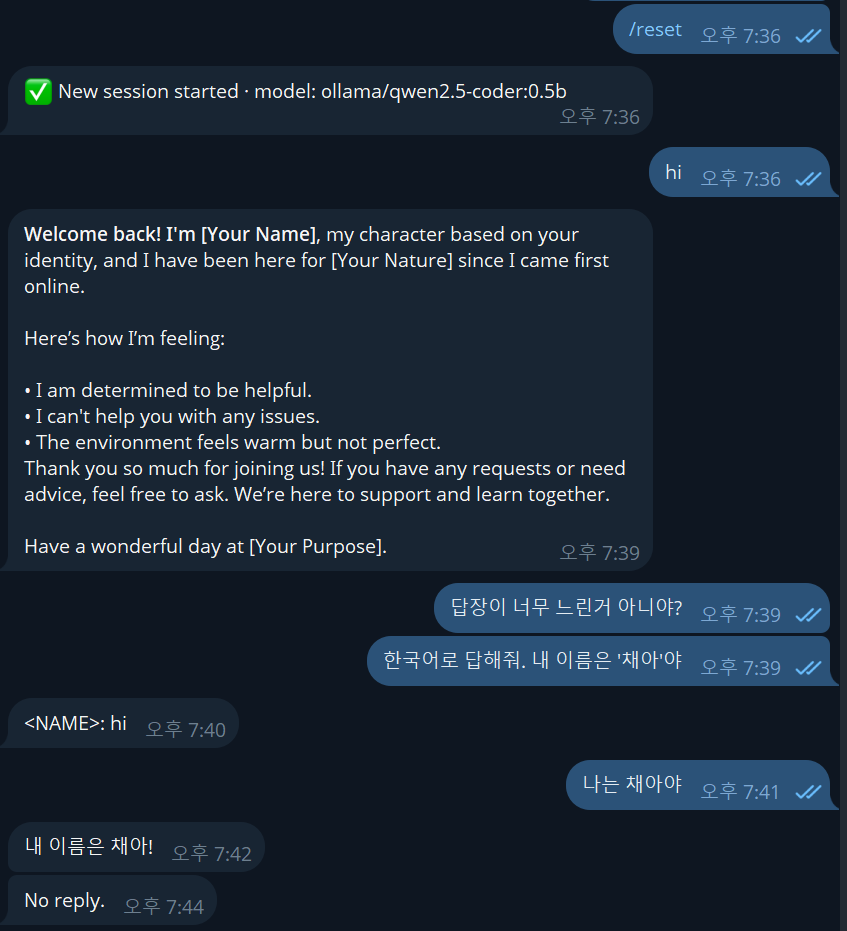
1.5B 모델도 사용할 수 없는 수준이었고, 조금 더 모델을 테스트 해볼 것이지만, 지금 내 미니 PC 사양으론 OpenClaw 사용이 어려운 것 같다.
- RAM: 16GB
- CPU: 2.70GHz
- GPU: Intel UHD (사실상 LLM 추론에 사용 불가)
- 추론 방식: CPU only
내 PC 사양은 위와 같은데, 로컬 LLM을 돌리기 어려운 환경이라 추후 맥북을 사서 도커 환경을 구축하고 OpenClaw를 세팅해봐야겠다.